
By Madhushan Adhikari

Caching is widely used methodology in current software development to enhance the performance of the system. Even if the caching makes the application modern and performance oriented, there are drawbacks when the caching is accessed from a distributed instance. A distributed cache is a type of cache that spans multiple servers or nodes, enabling the sharing, storing, and managing of cached data across a distributed system. Unlike traditional caching, which typically resides in a single location (like a server or in-memory cache on a single machine), distributed caching distributes the cached data across several locations to improve scalability, availability, and performance in large-scale applications. Before discussing about the distributed caching, let’s consider old fashion single instance-based caching. Let’s consider the below real-life scenario to make the concept easy to understand. E.g. Let’s consider a cache which holds data of a product inventory of a mobile shop. Assume currently it hold the data on below items and it has multiple branches.

Let’s consider the below three scenarios where
1) Only one instance of data read and write.
2) Only one instance of data write, and multiple instance of data read.
3) Multiple instances of data write, and multiple instance of data read.
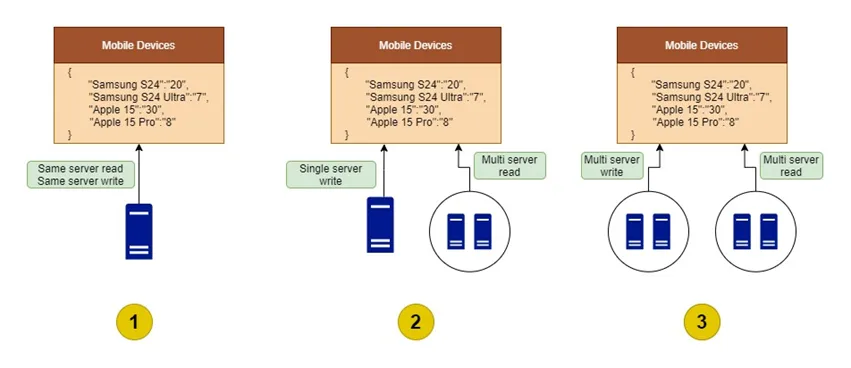
If we deep dive to these cases, number (1) and (2) will run smoothly without any inconsistency. But number (3) has a significant risk of getting data inconsistency if same object is updated by multiple instance at same time. If you a re design this application as a Java based application, Redis is the best choice available out there to handle this kind of complex situations.
Redis stands for REmote DIctionary Server and is an open-source, in-memory data structure store that is often used as a database, cache, and message broker. Developed by Salvatore Sanfilippo in 2009, Redis is designed to deliver sub-millisecond response times and support high-throughput operations, making it ideal for performance-critical applications. The key features in Redis are,
1) Redis stores all data in memory, which allows for extremely fast data access compared to disk-based databases
2) Redis is not just a key-value store; it supports a wide variety of data structures, including:
· Strings, Lists, Sets, Sorted Sets, Hashes, Bitmaps, HyperLogLogs, Geospatial Indexes, Streams
3) Persistence:
· Although Redis is primarily an in-memory store, it offers persistence options:
i. RDB (Redis Database File): A point-in-time snapshot of the dataset at specified intervals.
ii. AOF (Append-Only File): Logs every write operation to disk, which can be replayed to reconstruct the dataset.
· These mechanisms allow Redis to recover data after a restart or crash, combining the speed of an in-memory database with the reliability of disk storage.
4) Replication
5) High Availability with Redis Sentinel
6) Clustering
7) Transactions
8) Pub/Sub Messaging
And many more. But todays focus is mainly on how Redis is extended to Redisson to operates at a higher level, abstracting Redis commands into Java-friendly interfaces and providing additional distributed services.
Redisson is a Redis-based framework for Java that offers a wide range of tools and abstractions for building distributed applications. It provides implementations for Java’s Map, Set, List, Queue, and other collections, allowing them to be distributed across multiple servers. Redisson also supports distributed locking, atomic variables, semaphores, and more, making it a powerful tool for distributed caching and synchronization.
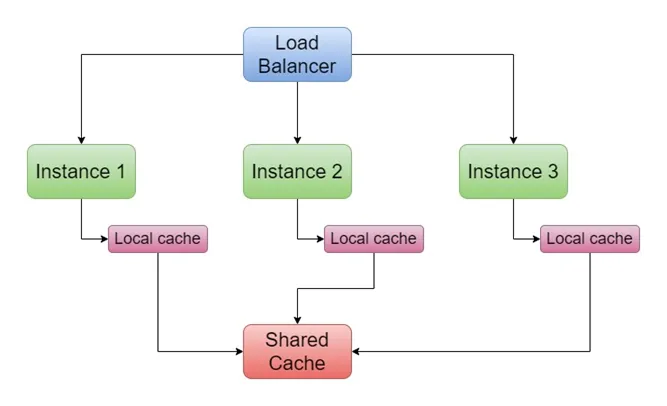
As illustrated in the diagram, the program running on each instance first checks the local cache, then the shared cache, and finally the persistent storage to verify data availability. In this approach the performance is not the issue. Higher performance can be obtained from this pattern. But the concern comes when the data is synced between multiple instances. If data is not properly synced, the application will contain invalid data, and the business process will result incorrect output.
In this kind of complex situations, Reddisson is the best option. The main problem of this kind scenario is to sync the data in the distributed caching instances and make sure that write operation does not violate the real value of the cache object. Reddison has an inbuild distributed locking mechanism where from application instance a write lock can be applied and if the same object accessed by another instance, it won’t be available until the lock is released. But in this mechanism, there is a disadvantage. This could cause a severe performance issue where if the same object is being accessed for large number of transactions, the waiting time would be huge. To avoid this, Redisson has inbuild distributed thread safe data structures like
These kind of data structures simplifies the development of concurrent and distributed Java applications, and the terminology will also be familiar to the Java syntax as well. In conclusion, Redisson is a rich framework to manage distributed caches with many inbuild feature and one of the best opensource alternative available in the market to develop better Java applications with distributed cache.

